
Analyzing exam scores#
📖 Background#
Client is an administrator at a large school. The school makes every student take year-end math, reading, and writing exams.
Let’s analyze the score results. The school’s principal wants to know if test preparation courses are helpful. She also wants to explore the effect of parental education level on test scores.
💾 The data#
The file has the following fields (source):#
“gender” - male / female
“race/ethnicity” - one of 5 combinations of race/ethnicity
“parent_education_level” - highest education level of either parent
“lunch” - whether the student receives free/reduced or standard lunch
“test_prep_course” - whether the student took the test preparation course
“math” - exam score in math
“reading” - exam score in reading
“writing” - exam score in writing
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('ggplot')
# Reading in the data
df = pd.read_csv('data/exams.csv')
# Take a look at the first datapoints
df.head()
| gender | race/ethnicity | parent_education_level | lunch | test_prep_course | math | reading | writing | |
|---|---|---|---|---|---|---|---|---|
| 0 | female | group B | bachelor's degree | standard | none | 72 | 72 | 74 |
| 1 | female | group C | some college | standard | completed | 69 | 90 | 88 |
| 2 | female | group B | master's degree | standard | none | 90 | 95 | 93 |
| 3 | male | group A | associate's degree | free/reduced | none | 47 | 57 | 44 |
| 4 | male | group C | some college | standard | none | 76 | 78 | 75 |
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 gender 1000 non-null object
1 race/ethnicity 1000 non-null object
2 parent_education_level 1000 non-null object
3 lunch 1000 non-null object
4 test_prep_course 1000 non-null object
5 math 1000 non-null int64
6 reading 1000 non-null int64
7 writing 1000 non-null int64
dtypes: int64(3), object(5)
memory usage: 62.6+ KB
df.describe()
| math | reading | writing | |
|---|---|---|---|
| count | 1000.00000 | 1000.000000 | 1000.000000 |
| mean | 66.08900 | 69.169000 | 68.054000 |
| std | 15.16308 | 14.600192 | 15.195657 |
| min | 0.00000 | 17.000000 | 10.000000 |
| 25% | 57.00000 | 59.000000 | 57.750000 |
| 50% | 66.00000 | 70.000000 | 69.000000 |
| 75% | 77.00000 | 79.000000 | 79.000000 |
| max | 100.00000 | 100.000000 | 100.000000 |
df.isnull().sum()
gender 0
race/ethnicity 0
parent_education_level 0
lunch 0
test_prep_course 0
math 0
reading 0
writing 0
dtype: int64
What are the average reading scores for students with/without the test preparation course?#
avg_reading_scores = df.groupby(['test_prep_course']).mean()['reading'].reset_index()
ax = sns.barplot(data=avg_reading_scores, x='test_prep_course', y='reading')
ax.set_title('Average reading scores for students with/without the test preperation course')
ax.set_ylabel('Reading Exam Score')
ax.set_xlabel('Test Preparation Course')
for p in ax.patches:
ax.annotate(format(p.get_height(), '.1f'),
(p.get_x() + p.get_width() / 2., p.get_height()-10),
ha = 'center', va = 'center',
xytext = (0, 9),
textcoords = 'offset points')
plt.show()
---------------------------------------------------------------------------
NotImplementedError Traceback (most recent call last)
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/groupby/groupby.py:1490, in GroupBy._cython_agg_general.<locals>.array_func(values)
1489 try:
-> 1490 result = self.grouper._cython_operation(
1491 "aggregate",
1492 values,
1493 how,
1494 axis=data.ndim - 1,
1495 min_count=min_count,
1496 **kwargs,
1497 )
1498 except NotImplementedError:
1499 # generally if we have numeric_only=False
1500 # and non-applicable functions
1501 # try to python agg
1502 # TODO: shouldn't min_count matter?
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/groupby/ops.py:959, in BaseGrouper._cython_operation(self, kind, values, how, axis, min_count, **kwargs)
958 ngroups = self.ngroups
--> 959 return cy_op.cython_operation(
960 values=values,
961 axis=axis,
962 min_count=min_count,
963 comp_ids=ids,
964 ngroups=ngroups,
965 **kwargs,
966 )
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/groupby/ops.py:657, in WrappedCythonOp.cython_operation(self, values, axis, min_count, comp_ids, ngroups, **kwargs)
649 return self._ea_wrap_cython_operation(
650 values,
651 min_count=min_count,
(...)
654 **kwargs,
655 )
--> 657 return self._cython_op_ndim_compat(
658 values,
659 min_count=min_count,
660 ngroups=ngroups,
661 comp_ids=comp_ids,
662 mask=None,
663 **kwargs,
664 )
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/groupby/ops.py:497, in WrappedCythonOp._cython_op_ndim_compat(self, values, min_count, ngroups, comp_ids, mask, result_mask, **kwargs)
495 return res.T
--> 497 return self._call_cython_op(
498 values,
499 min_count=min_count,
500 ngroups=ngroups,
501 comp_ids=comp_ids,
502 mask=mask,
503 result_mask=result_mask,
504 **kwargs,
505 )
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/groupby/ops.py:541, in WrappedCythonOp._call_cython_op(self, values, min_count, ngroups, comp_ids, mask, result_mask, **kwargs)
540 out_shape = self._get_output_shape(ngroups, values)
--> 541 func = self._get_cython_function(self.kind, self.how, values.dtype, is_numeric)
542 values = self._get_cython_vals(values)
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/groupby/ops.py:173, in WrappedCythonOp._get_cython_function(cls, kind, how, dtype, is_numeric)
171 if "object" not in f.__signatures__:
172 # raise NotImplementedError here rather than TypeError later
--> 173 raise NotImplementedError(
174 f"function is not implemented for this dtype: "
175 f"[how->{how},dtype->{dtype_str}]"
176 )
177 return f
NotImplementedError: function is not implemented for this dtype: [how->mean,dtype->object]
During handling of the above exception, another exception occurred:
ValueError Traceback (most recent call last)
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/nanops.py:1692, in _ensure_numeric(x)
1691 try:
-> 1692 x = float(x)
1693 except (TypeError, ValueError):
1694 # e.g. "1+1j" or "foo"
ValueError: could not convert string to float: 'femalefemalemalemalemalefemalemalemalefemalemalefemalefemalemalemalefemalefemalemalemalefemalemalemalefemalemalemalemalemalefemalemalemalemalemalefemalefemalefemalemalefemalemalemalemalefemalemalemalemalefemalefemalemalemalefemalefemalefemalefemalemalefemalefemalemalefemalefemalefemalemalefemalefemalefemalefemalefemalefemalemalemalemalemalemalemalefemalemalefemalemalemalemalemalemalemalefemalemalefemalefemalefemalemalefemalemalefemalemalefemalemalefemalefemalemalefemalemalefemalefemalefemalemalemalemalemalemalemalemalemalemalefemalefemalemalemalefemalefemalefemalefemalemalemalemalefemalefemalemalefemalefemalefemalemalemalemalefemalefemalefemalemalemalemalefemalefemalefemalemalefemalemalefemalemalemalefemalemalemalefemalefemalefemalefemalemalemalefemalefemalemalefemalemalemalemalefemalefemalefemalefemalefemalemalemalemalemalemalefemalefemalefemalefemalefemalefemalefemalefemalefemalemalemalefemalemalefemalemalefemalemalemalemalemalemalemalefemalemalemalefemalefemalemalefemalefemalefemalemalefemalemalemalefemalefemalefemalefemalemalemalemalemalemalemalemalemalefemalefemalefemalefemalefemalefemalefemalefemalemalefemalefemalefemalefemalefemalemalefemalefemalefemalefemalefemalefemalemalefemalemalefemalefemalefemalefemalemalefemalefemalemalefemalefemalefemalemalefemalemalemalefemalemalefemalemalefemalefemalefemalefemalemalemalemalefemalemalefemalemalemalefemalemalefemalefemalemalefemalefemalemalefemalemalefemalemalemalefemalemalemalemalefemalemalefemalefemalefemalefemalefemalefemalemalefemalemalefemalemalemalemalefemalemalemalefemalemalemalefemalefemalefemalefemalemalefemalemalefemalefemalefemalefemalemalefemalefemalemalefemalemalemalefemalemalemalemalemalemalemalemalemalemalemalefemalefemalemalefemalemalemalefemalefemalemalemalemalefemalemalefemalemalefemalefemalefemalefemale'
During handling of the above exception, another exception occurred:
ValueError Traceback (most recent call last)
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/nanops.py:1696, in _ensure_numeric(x)
1695 try:
-> 1696 x = complex(x)
1697 except ValueError as err:
1698 # e.g. "foo"
ValueError: complex() arg is a malformed string
The above exception was the direct cause of the following exception:
TypeError Traceback (most recent call last)
Cell In[6], line 1
----> 1 avg_reading_scores = df.groupby(['test_prep_course']).mean()['reading'].reset_index()
2 ax = sns.barplot(data=avg_reading_scores, x='test_prep_course', y='reading')
3 ax.set_title('Average reading scores for students with/without the test preperation course')
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/groupby/groupby.py:1855, in GroupBy.mean(self, numeric_only, engine, engine_kwargs)
1853 return self._numba_agg_general(sliding_mean, engine_kwargs)
1854 else:
-> 1855 result = self._cython_agg_general(
1856 "mean",
1857 alt=lambda x: Series(x).mean(numeric_only=numeric_only),
1858 numeric_only=numeric_only,
1859 )
1860 return result.__finalize__(self.obj, method="groupby")
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/groupby/groupby.py:1507, in GroupBy._cython_agg_general(self, how, alt, numeric_only, min_count, **kwargs)
1503 result = self._agg_py_fallback(values, ndim=data.ndim, alt=alt)
1505 return result
-> 1507 new_mgr = data.grouped_reduce(array_func)
1508 res = self._wrap_agged_manager(new_mgr)
1509 out = self._wrap_aggregated_output(res)
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/internals/managers.py:1503, in BlockManager.grouped_reduce(self, func)
1499 if blk.is_object:
1500 # split on object-dtype blocks bc some columns may raise
1501 # while others do not.
1502 for sb in blk._split():
-> 1503 applied = sb.apply(func)
1504 result_blocks = extend_blocks(applied, result_blocks)
1505 else:
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/internals/blocks.py:329, in Block.apply(self, func, **kwargs)
323 @final
324 def apply(self, func, **kwargs) -> list[Block]:
325 """
326 apply the function to my values; return a block if we are not
327 one
328 """
--> 329 result = func(self.values, **kwargs)
331 return self._split_op_result(result)
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/groupby/groupby.py:1503, in GroupBy._cython_agg_general.<locals>.array_func(values)
1490 result = self.grouper._cython_operation(
1491 "aggregate",
1492 values,
(...)
1496 **kwargs,
1497 )
1498 except NotImplementedError:
1499 # generally if we have numeric_only=False
1500 # and non-applicable functions
1501 # try to python agg
1502 # TODO: shouldn't min_count matter?
-> 1503 result = self._agg_py_fallback(values, ndim=data.ndim, alt=alt)
1505 return result
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/groupby/groupby.py:1457, in GroupBy._agg_py_fallback(self, values, ndim, alt)
1452 ser = df.iloc[:, 0]
1454 # We do not get here with UDFs, so we know that our dtype
1455 # should always be preserved by the implemented aggregations
1456 # TODO: Is this exactly right; see WrappedCythonOp get_result_dtype?
-> 1457 res_values = self.grouper.agg_series(ser, alt, preserve_dtype=True)
1459 if isinstance(values, Categorical):
1460 # Because we only get here with known dtype-preserving
1461 # reductions, we cast back to Categorical.
1462 # TODO: if we ever get "rank" working, exclude it here.
1463 res_values = type(values)._from_sequence(res_values, dtype=values.dtype)
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/groupby/ops.py:994, in BaseGrouper.agg_series(self, obj, func, preserve_dtype)
987 if len(obj) > 0 and not isinstance(obj._values, np.ndarray):
988 # we can preserve a little bit more aggressively with EA dtype
989 # because maybe_cast_pointwise_result will do a try/except
990 # with _from_sequence. NB we are assuming here that _from_sequence
991 # is sufficiently strict that it casts appropriately.
992 preserve_dtype = True
--> 994 result = self._aggregate_series_pure_python(obj, func)
996 npvalues = lib.maybe_convert_objects(result, try_float=False)
997 if preserve_dtype:
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/groupby/ops.py:1015, in BaseGrouper._aggregate_series_pure_python(self, obj, func)
1012 splitter = self._get_splitter(obj, axis=0)
1014 for i, group in enumerate(splitter):
-> 1015 res = func(group)
1016 res = libreduction.extract_result(res)
1018 if not initialized:
1019 # We only do this validation on the first iteration
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/groupby/groupby.py:1857, in GroupBy.mean.<locals>.<lambda>(x)
1853 return self._numba_agg_general(sliding_mean, engine_kwargs)
1854 else:
1855 result = self._cython_agg_general(
1856 "mean",
-> 1857 alt=lambda x: Series(x).mean(numeric_only=numeric_only),
1858 numeric_only=numeric_only,
1859 )
1860 return result.__finalize__(self.obj, method="groupby")
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/generic.py:11556, in NDFrame._add_numeric_operations.<locals>.mean(self, axis, skipna, numeric_only, **kwargs)
11539 @doc(
11540 _num_doc,
11541 desc="Return the mean of the values over the requested axis.",
(...)
11554 **kwargs,
11555 ):
> 11556 return NDFrame.mean(self, axis, skipna, numeric_only, **kwargs)
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/generic.py:11201, in NDFrame.mean(self, axis, skipna, numeric_only, **kwargs)
11194 def mean(
11195 self,
11196 axis: Axis | None = 0,
(...)
11199 **kwargs,
11200 ) -> Series | float:
> 11201 return self._stat_function(
11202 "mean", nanops.nanmean, axis, skipna, numeric_only, **kwargs
11203 )
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/generic.py:11158, in NDFrame._stat_function(self, name, func, axis, skipna, numeric_only, **kwargs)
11154 nv.validate_stat_func((), kwargs, fname=name)
11156 validate_bool_kwarg(skipna, "skipna", none_allowed=False)
> 11158 return self._reduce(
11159 func, name=name, axis=axis, skipna=skipna, numeric_only=numeric_only
11160 )
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/series.py:4670, in Series._reduce(self, op, name, axis, skipna, numeric_only, filter_type, **kwds)
4665 raise TypeError(
4666 f"Series.{name} does not allow {kwd_name}={numeric_only} "
4667 "with non-numeric dtypes."
4668 )
4669 with np.errstate(all="ignore"):
-> 4670 return op(delegate, skipna=skipna, **kwds)
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/nanops.py:96, in disallow.__call__.<locals>._f(*args, **kwargs)
94 try:
95 with np.errstate(invalid="ignore"):
---> 96 return f(*args, **kwargs)
97 except ValueError as e:
98 # we want to transform an object array
99 # ValueError message to the more typical TypeError
100 # e.g. this is normally a disallowed function on
101 # object arrays that contain strings
102 if is_object_dtype(args[0]):
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/nanops.py:158, in bottleneck_switch.__call__.<locals>.f(values, axis, skipna, **kwds)
156 result = alt(values, axis=axis, skipna=skipna, **kwds)
157 else:
--> 158 result = alt(values, axis=axis, skipna=skipna, **kwds)
160 return result
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/nanops.py:421, in _datetimelike_compat.<locals>.new_func(values, axis, skipna, mask, **kwargs)
418 if datetimelike and mask is None:
419 mask = isna(values)
--> 421 result = func(values, axis=axis, skipna=skipna, mask=mask, **kwargs)
423 if datetimelike:
424 result = _wrap_results(result, orig_values.dtype, fill_value=iNaT)
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/nanops.py:727, in nanmean(values, axis, skipna, mask)
724 dtype_count = dtype
726 count = _get_counts(values.shape, mask, axis, dtype=dtype_count)
--> 727 the_sum = _ensure_numeric(values.sum(axis, dtype=dtype_sum))
729 if axis is not None and getattr(the_sum, "ndim", False):
730 count = cast(np.ndarray, count)
File /opt/hostedtoolcache/Python/3.8.17/x64/lib/python3.8/site-packages/pandas/core/nanops.py:1699, in _ensure_numeric(x)
1696 x = complex(x)
1697 except ValueError as err:
1698 # e.g. "foo"
-> 1699 raise TypeError(f"Could not convert {x} to numeric") from err
1700 return x
TypeError: Could not convert femalefemalemalemalemalefemalemalemalefemalemalefemalefemalemalemalefemalefemalemalemalefemalemalemalefemalemalemalemalemalefemalemalemalemalemalefemalefemalefemalemalefemalemalemalemalefemalemalemalemalefemalefemalemalemalefemalefemalefemalefemalemalefemalefemalemalefemalefemalefemalemalefemalefemalefemalefemalefemalefemalemalemalemalemalemalemalefemalemalefemalemalemalemalemalemalemalefemalemalefemalefemalefemalemalefemalemalefemalemalefemalemalefemalefemalemalefemalemalefemalefemalefemalemalemalemalemalemalemalemalemalemalefemalefemalemalemalefemalefemalefemalefemalemalemalemalefemalefemalemalefemalefemalefemalemalemalemalefemalefemalefemalemalemalemalefemalefemalefemalemalefemalemalefemalemalemalefemalemalemalefemalefemalefemalefemalemalemalefemalefemalemalefemalemalemalemalefemalefemalefemalefemalefemalemalemalemalemalemalefemalefemalefemalefemalefemalefemalefemalefemalefemalemalemalefemalemalefemalemalefemalemalemalemalemalemalemalefemalemalemalefemalefemalemalefemalefemalefemalemalefemalemalemalefemalefemalefemalefemalemalemalemalemalemalemalemalemalefemalefemalefemalefemalefemalefemalefemalefemalemalefemalefemalefemalefemalefemalemalefemalefemalefemalefemalefemalefemalemalefemalemalefemalefemalefemalefemalemalefemalefemalemalefemalefemalefemalemalefemalemalemalefemalemalefemalemalefemalefemalefemalefemalemalemalemalefemalemalefemalemalemalefemalemalefemalefemalemalefemalefemalemalefemalemalefemalemalemalefemalemalemalemalefemalemalefemalefemalefemalefemalefemalefemalemalefemalemalefemalemalemalemalefemalemalemalefemalemalemalefemalefemalefemalefemalemalefemalemalefemalefemalefemalefemalemalefemalefemalemalefemalemalemalefemalemalemalemalemalemalemalemalemalemalemalefemalefemalemalefemalemalemalefemalefemalemalemalemalefemalemalefemalemalefemalefemalefemalefemale to numeric
Observation#
Students that completed the test preperation course on average scored higher on the reading exam compared to students who didn’t.
What are the average scores for the different parental education levels?#
# Aggregate all 3 exams together
df['all_exams'] = df[['math', 'reading', 'writing']].mean(axis=1)
avg_scores_by_parent_edu = df.groupby(['parent_education_level']).mean()
# Sort index by ascending Education Level
sort_edu_level = {"some high school": 0, "high school": 1, "some college": 2, "associate's degree": 3, "bachelor's degree": 4, "master's degree": 5}
avg_scores_by_parent_edu.sort_index(key=lambda x: x.map(sort_edu_level), inplace=True)
fig, axs = plt.subplots(4, 1, figsize=(15,15))
fig.tight_layout()
axs[0].bar(avg_scores_by_parent_edu.index, avg_scores_by_parent_edu['math'], color='pink', label='math')
axs[0].set_ylabel('Math Exam Score')
axs[1].bar(avg_scores_by_parent_edu.index, avg_scores_by_parent_edu['reading'], color='lightblue', label='reading')
axs[1].set_ylabel('Reading Exam Score')
axs[2].bar(avg_scores_by_parent_edu.index, avg_scores_by_parent_edu['writing'], color='lightgreen', label='writing')
axs[2].set_ylabel('Writing Exam Score')
axs[3].bar(avg_scores_by_parent_edu.index, avg_scores_by_parent_edu['all_exams'], color='yellow', label='all_exams')
axs[3].set_ylabel('Overall Exam Scores')
fig.suptitle('Average Exam Score by Parent Education Level', y=1.02)
for ax in axs:
for p in ax.patches:
ax.annotate(format(p.get_height(), '.1f'),
(p.get_x() + p.get_width() / 2., p.get_height()-10),
ha = 'center', va = 'center',
xytext = (0, 9),
textcoords = 'offset points')
plt.show()
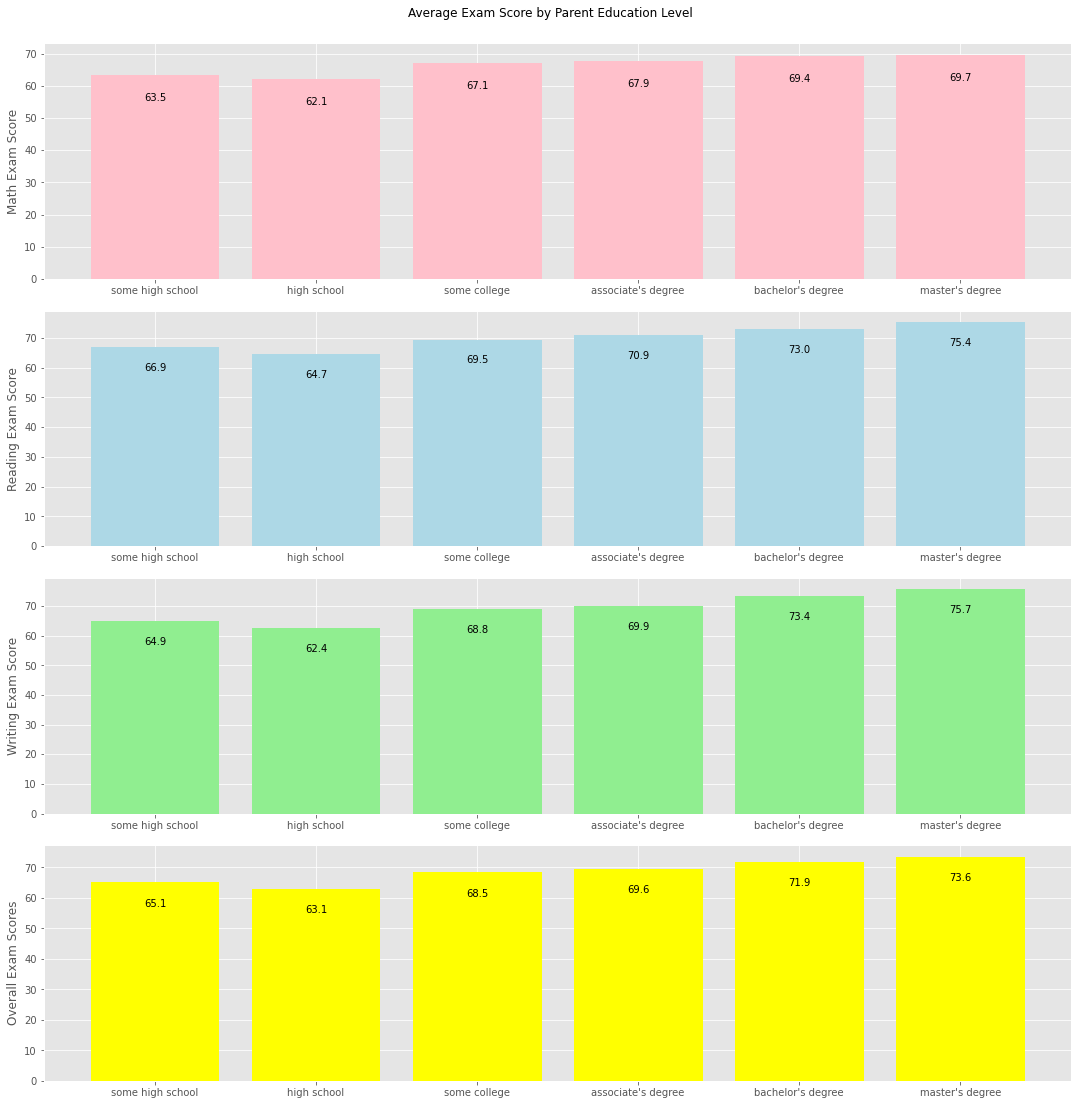
Observation#
Overall, there is a positive trend between average exam scores and parental education levels, where a higher education level means a high exam score.
Assuming that some high school means that the parent didn’t graduate high school: the average scores for high school is an outlier to this trend, because it is lower than some high school.
Average scores for students with/without the test preparation course for different parental education levels#
# Aggregate all 3 exams together
df['all_exams'] = df[['math', 'reading', 'writing']].mean(axis=1)
# Split by whether copmleted Test Prep Course
completed = df.test_prep_course == 'completed'
avg_scores_by_parent_edu_completed = df[completed].groupby(['parent_education_level']).mean()
avg_scores_by_parent_edu_no_prep = df[~completed].groupby(['parent_education_level']).mean()
# Sort index by ascending Education Level
sort_edu_level = {"some high school": 0, "high school": 1, "some college": 2, "associate's degree": 3, "bachelor's degree": 4, "master's degree": 5}
avg_scores_by_parent_edu_completed.sort_index(key=lambda x: x.map(sort_edu_level), inplace=True)
avg_scores_by_parent_edu_no_prep.sort_index(key=lambda x: x.map(sort_edu_level), inplace=True)
N = 6
ind = np.arange(N)
width = 0.25
plt.figure(figsize=(15,5))
plt.bar(ind, avg_scores_by_parent_edu_completed['all_exams'], color = 'b',
width = width, edgecolor = 'black',
label='Completed')
plt.bar(ind+width, avg_scores_by_parent_edu_no_prep['all_exams'], color = 'g',
width = width, edgecolor = 'black',
label='None')
plt.xticks(ind + width/2, avg_scores_by_parent_edu.index)
plt.xlabel('Parent Education Level')
plt.ylabel('Exam Score')
plt.title('Average scores for students with/without the test preparation course for different parental education levels')
plt.legend()
plt.show()
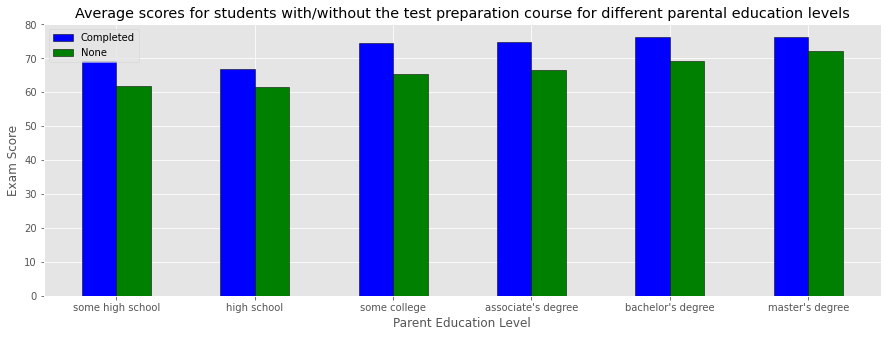
Observation#
Across all parental education levels, students that completed the test preparation course on average scored higher on the exams compared to students that didn’t.
If kids who perform well on one subject also score well on the others#
plt.figure(figsize=(15,5))
sns.heatmap(df[['math', 'reading', 'writing']].corr(), annot=True)
plt.title('Correlation of exam scores between subjects')
plt.show()
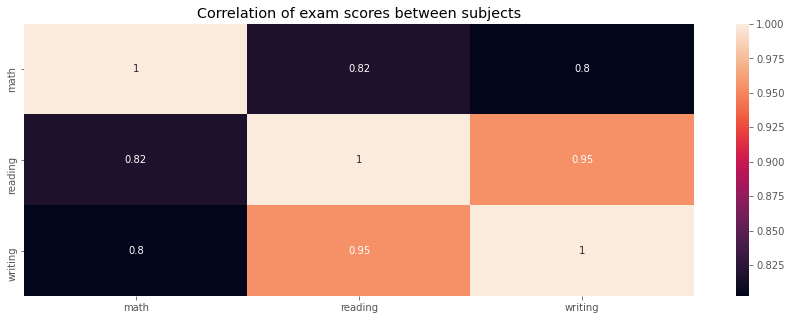
Observation#
There is strong positive correlations between students that well on one subject and others.
Particularly, there is a high 0.95 correlation between scoring well on the reading and writing exam, likely because they are closely related subjects.
Summary#
The average reading scores for students with the test prepartion course: 73.9.
The average reading scores for students without the test prepartion course: 66.5.
The positive relationship between average exam score and parental education levels.
Across all parental education levels, students that completed the test preparation course on average scored higher on the exams compared to students that didn’t.
There is strong positive correlations between students that well on one subject and others.